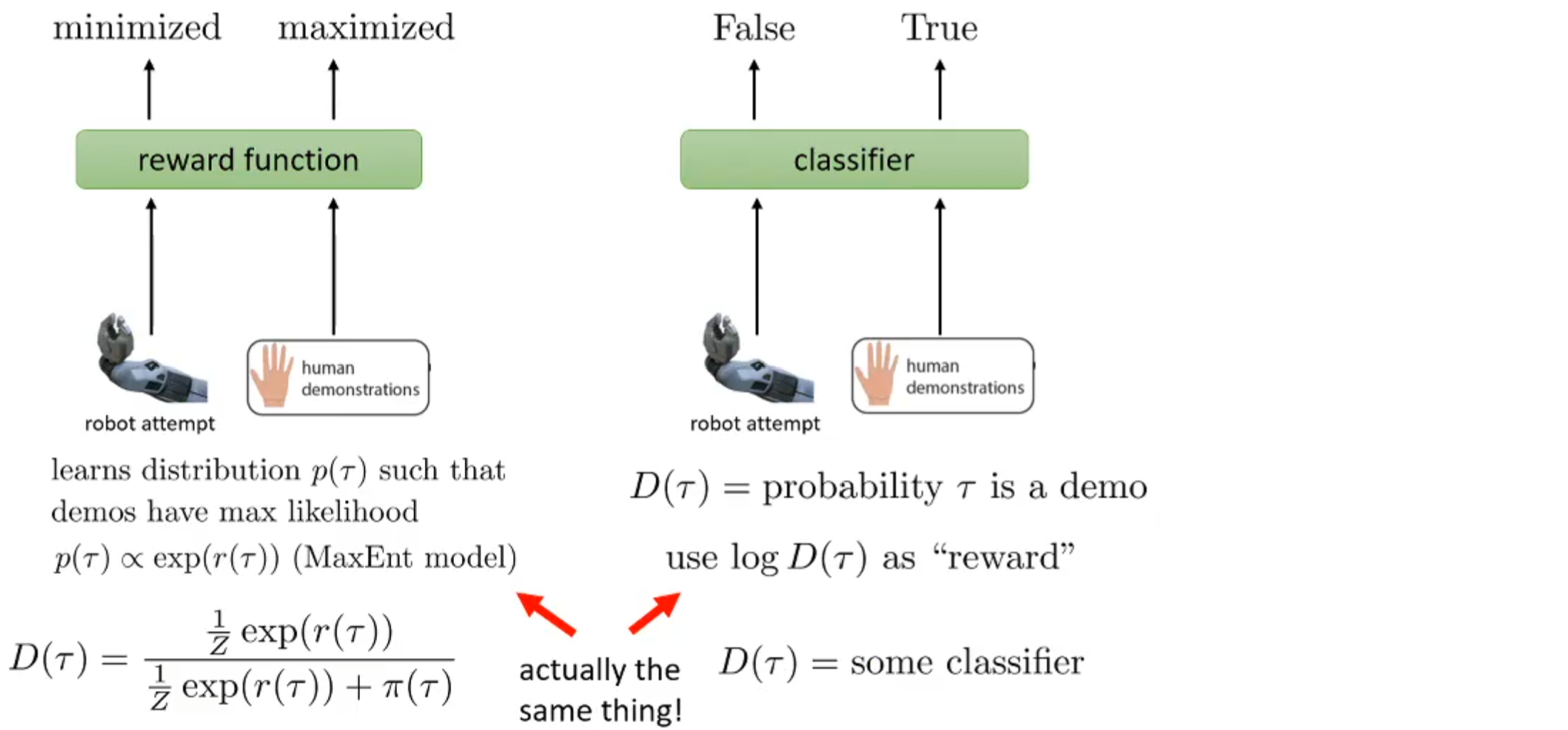
Inverse Reinforcement Learning
使用上节课学习的近似最优模型来获得一个 reward
Why IRL?
如果是理性的推理,可以逐步优化。机器模仿学习往往学习精确的动作,而人类模仿学习会尝试推理对方的意图。有的情况下,reward 并没有那么显然,可能综合考虑了多种因素,所以通过行为推导出 reward 有一定的难度。此外,对于同一种目标行为,可以有多种奖励函数来定义。通过演示推断奖励函数,有多种结果。
形式化定义
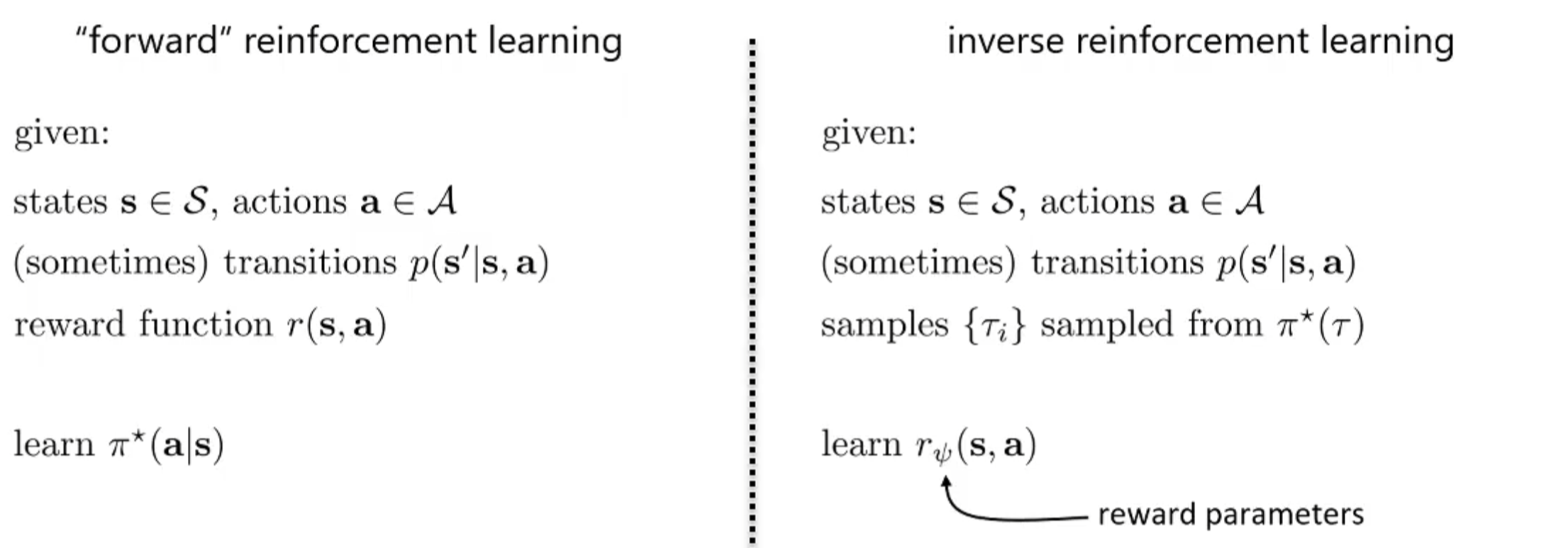
例如可以使用:,也可以使用神经网络针对 输出对应的奖励。
Feature matching IRL
有一些特征,学习奖励函数,使特征的期望最大。假设 是 的最优策略,我们需要选择 使得 。
feature: 例如对自动驾驶任务,可以定义为:较少闯红灯,较少急减速,较少发生碰撞……
但是这里存在歧义,因为不同的 可能有相同的特征期望。为了应对歧义,我们可以进一步定义:
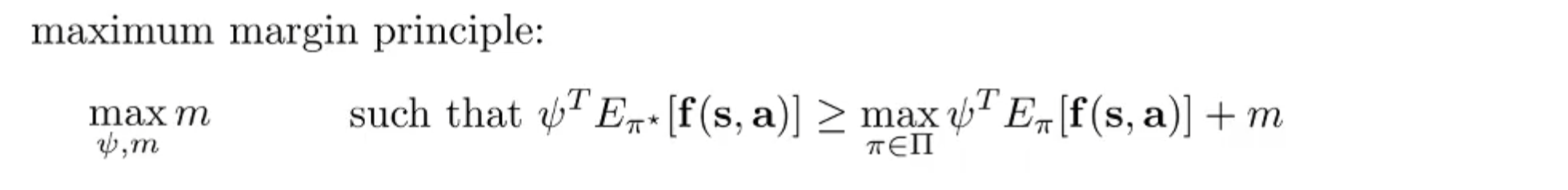
为了区分与专家策略接近的策略,需要找到与 衡量的方式。使用 SVM:通过拉格朗日对偶性,将问题重写为:
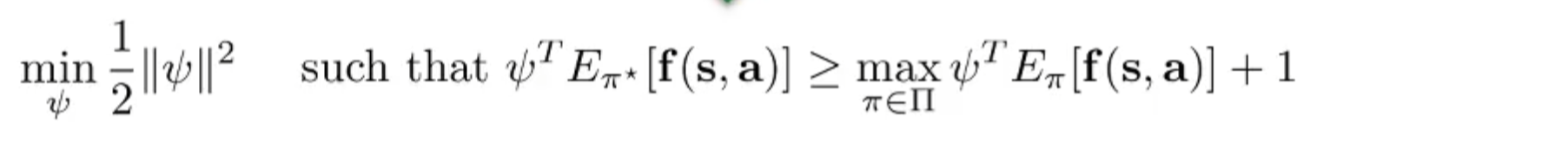
可以进一步引入策略之间的相似性:
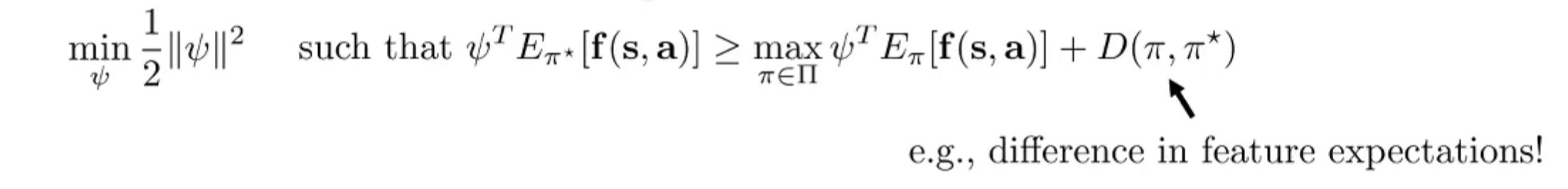
以上的方法遇到了一些问题:
- 我们的最终目的是找到一个专家策略,明显比其他策略好!但是这里往往有任意性。
- 没有关于专家的非最优性行为的清晰模型,无法解释为什么有时候专家也无法做出最优的决策。
- 在这个优化问题中,约束条件相对复杂,神经网络不容易学习。
所以这里尝试使用 Optimal Control 来模拟人类的行为:
在最优控制中:不预先假设行为主体一定是“最优”的,为了在概率模型里刻画“高回报轨迹更可能出现”,我们给每个时间步 t 增加一个二值随机变量 ,表示“在时刻 t,动作 在状态 下是“最优”的(optimal)”。需要求 ,定义 ,即 reward 越大可能更优。又已知:
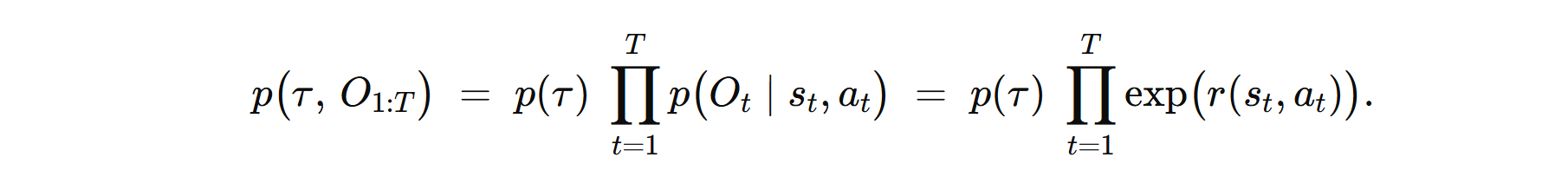
通过条件概率,
Learning Reward Functions
考虑参数 :,通过最大似然估计:, 作为正则项,。
进一步求导化简为:
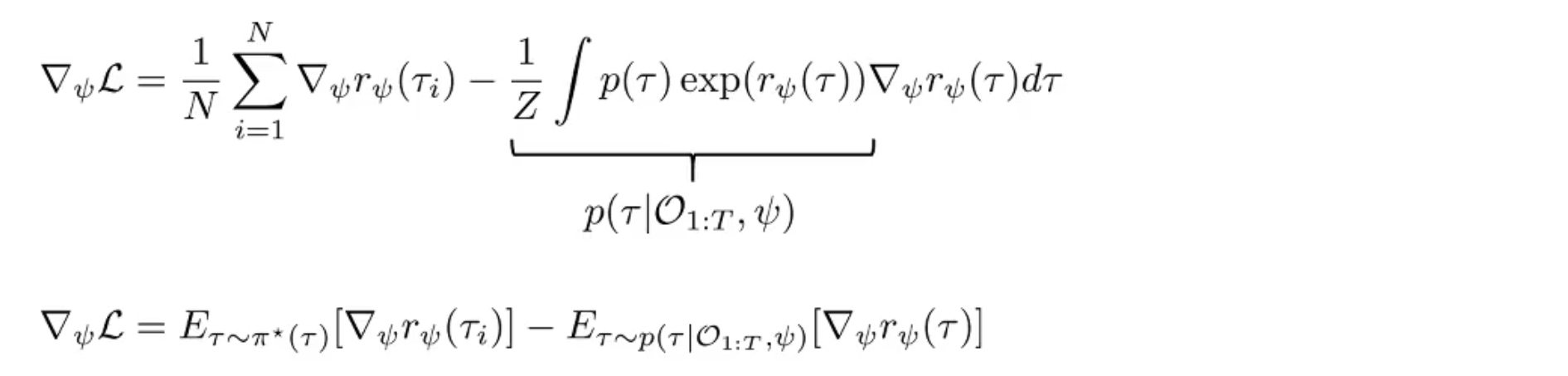
其中第一项是对专家策略的估计,第二项是当前奖励下的软最优策略。根据上一节的内容,拆解为 forward 和 backward message 两部分,可以带入 和 。这里就引出了:
Max entropy IRL

奖励越高,说明专家的行为越确定。
Approximation in High Dimensions
假设不知道 dynamic 但是可以采样:
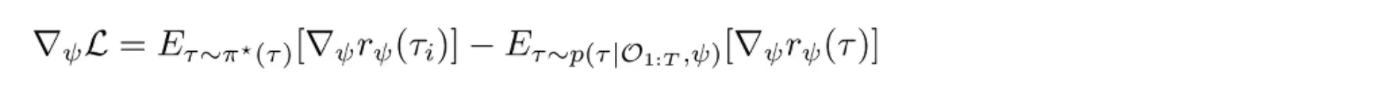
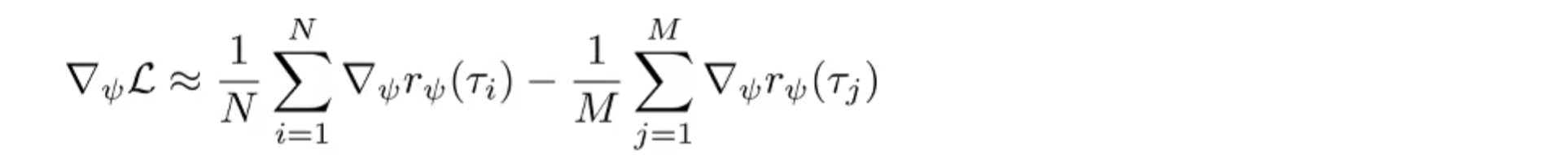
但是这样是有偏的,需要重要性采样:
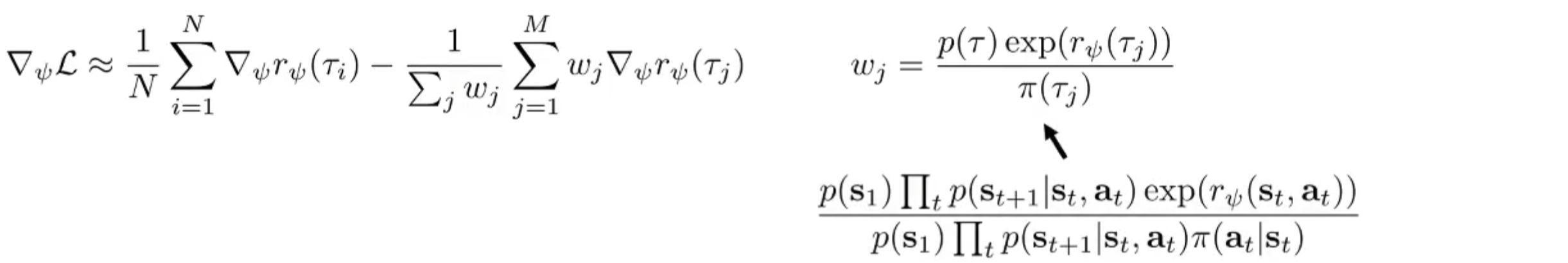
然后使用 policy gradient 更新 :

随着策略的奖励变高,当前最优策略的权重变高。
IRL and GANs
与 GAN 类似,根据 loss 的梯度可以发现,IRL 的更新当前的策略使其与演示策略的表现接近。
在 GAN 中使用以下的方式更新 discriminator
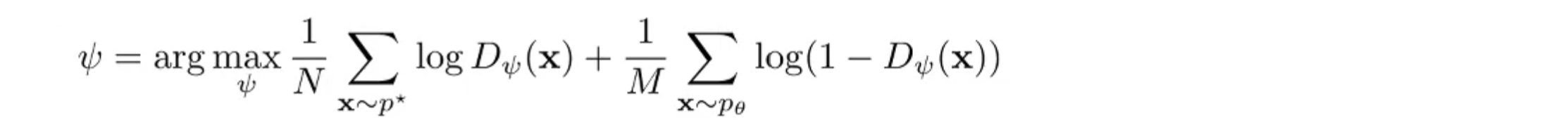
可以把 Inverse RL 看做 GAN:

这里不再需要重要性权重
Generalization via IRL
在学习 model 时,将 reward 和 dynamic 解耦,可以保证更好的迁移性。
discriminator 的分类器可以根据情况选择,但是如果对 discriminator 使用最简单的分类器,初期优化比较容易,但是当 generator 比较好时,discrimimator 将什么都不知道。
IRL as adversarial optimization